Inspecting packet drops
Once you have warned about receive side drops on NIC, it’s getting really serious. Just because Linux networking is a really complex piece of the kernel, it’s also hard to inspect these packet drops. I want to share some interesting info I managed to inspect.
The simplest way to check if you need some tuning is just called this script. BUT you can’t see the actual numbers, for example, you can’t see what’s the netdev_budget is available at the moment, what is the queue length for particular CPU.
I won’t talk about application level drops, like buffer’s overflow, backlogs, socket buffers and so on. I will talk about the lowest part of TCP/IP stack in Linux kernel regarding packet drops.
When the packet hits the NIC, NIC raises hardware interrupt. Interrupt calls soft IRQ handler to drain packets from NIC’s circular buffer (aka ring buffer). In general this is handled in net_rx_action(). The Kernel does sanity check according to netdev_budget to see how much packets it is allowed to drain from NIC in one polling cycle. Budget is the overall amount of packets net_rx_action() is able to drain from ring buffers. Polling is done using bursts by weight, which is typically 64 and it’s subtracted from netdev_budget. To see if a current netdev_budget value is enough, let’s employ systemtap:
probe kernel.statement("net_rx_action@net/core/dev.c:4464")
{
avail_budget = $budget - $work;
percentile = (avail_budget * 100) / $budget;
if (percentile < 50 && percentile >= 0)
printf("%d %d\n", cpu(), percentile);
}
This will show how much percentage current netdev_budget is busy. If it’s getting nearly zero, you have to raise this parameter even twice. Basically, if it’s nearly zero, you have problems, the kernel isn’t able to drain packets from NIC’s ring buffer, thus oldest packets residing in ring buffer gets overwritten, in short, dropped. Too high value is bad too because netdev_max_backlog is getting too high per CPU and packets will be dropped.
Another important option is netdev_max_backlog. It’s the input queue length per CPU. Once this queue is getting equal or higher than netdev_max_backlog, the packet is just dropped. There is no easy way to see these queues per CPU. The best way to watch that is to hook on enqueue_to_backlog(). For example:
%{
#include <linux/tcp.h>
%}
function get_queue_len:long(cpu:long)
%{
struct softnet_data *sd;
sd = &per_cpu(softnet_data, STAP_ARG_cpu);
THIS->__retvalue = skb_queue_len(&sd->input_pkt_queue);
%}
probe kernel.function("enqueue_to_backlog")
{
queue_length = get_queue_len($cpu);
if (queue_length)
printf("cpu: %d, queue: %d\n", $cpu, queue_length);
}
This will show what’s the input queue length for each CPU in real-time. After that, you are able to tune it appropriately.
Okay, but what about ring buffers? How are they managed?
Long story short: Ring buffer as you know is just nothing else as a circular buffer (implemented as an array or linked list), which means older packets are just dropped or overridden if the ring is too small. As in the example below, maximum ring buffer’s size is 4096 descriptors, which means these descriptors have to be poll quick. Unused descriptors are calculated like:
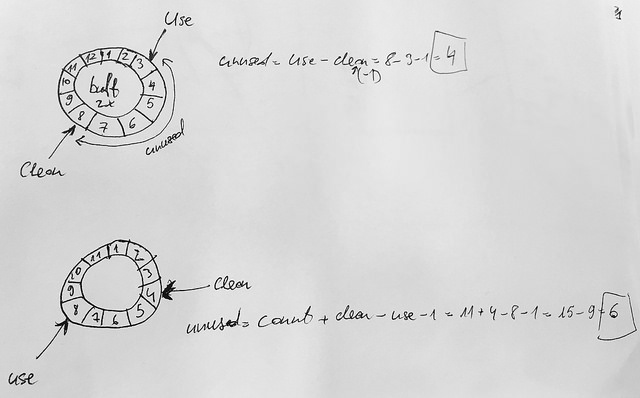
If next_to_clean > next_to_use, then free descriptor’s count is calculated just next_to_clean - next_to_use - 1
Else, total_descriptors + next_to_clean - next_to_use - 1
These two pointers next_to_use and next_to_clean are used by NIC’s driver and OS (kernel). next_to_use is used by NIC, while next_to_clean is used by the kernel to poll.
Well, that’s fine unless you do not have any problems like these:
probe module("ixgbe").statement("ixgbe_update_stats@drivers/net/ethernet/intel/ixgbe/ixgbe_main.c:5802")
{
if ($total_mpc || $missed_rx) {
for (i = 0; i < $adapter->num_rx_queues; i++) {
unused = $adapter->rx_ring[i]->count + $adapter->rx_ring[i]->next_to_clean - $adapter->rx_ring[i]->next_to_use - 1;
if ($adapter->rx_ring[i]->next_to_clean > $adapter->rx_ring[i]->next_to_use)
unused = $adapter->rx_ring[i]->next_to_clean - $adapter->rx_ring[i]->next_to_use - 1;
if (unused < 1)
printf("rx_ring: %d\n", i);
}
}
}
rx_ring: 18
rx_ring: 6
It means, that ring buffers for CPU IDs 6 and 18 (while you are using multi-queue NICs, which are able to write to separate DMA region for each CPU) are full and cannot be drained as expected. In this case, packets drop occurred.
Pabaiga
- How to avoid such situation? Rule #1 of good engineering again - know your problem ;-)
- Or in general, it depends: one could try to do busy polling from application layer if CPU time is free enough, other could try to avoid polling and do it using interrupt-driven fashion (lower latency, but not much performant);
- What I want to say, for 95% cases, defaults are good enough, do not over-configure what you do not understand, because it will break something else.