Scaling Chef Server
If you search on how to scale Chef Server, you are lucky, there is a SINGLE post in internets. I appreciate the author of this blog post which helped me go in the right direction (moving from standalone instance to multiple).
I’m gonna switch into German mode here and wanna give a big disappointment for Chef Community: it’s horrible, lack of proper documentation, authors of Chef suggesting do not use Chef (=huh?) or paying money - helpless, at all. Unlike Ansible. But let’s leave this topic untouched here.
Standalone Chef Server served well for a long time until reached more than 700 nodes with heavy searches and a non-optimized version of cookbooks. Scaling vertically was good enough until around 1000 nodes. It was kinda 4 CPU cores, later 8, 16, 32, and we are done here. Chef Server is CPU intensive, memory does not matter much.
The main CPU hungry process is erchef which is responsible for serving API requests for all necessary components: search, cookbooks, nodes, attributes, etc.
Then we start looking at the beforementioned blog post tuning recommendations, like enable cookbook caching, worker count tuning, timeouts, etc. Frankly speaking, it doesn’t help at all if you reach this state with 32 cores going at full rate.
I was randomly reminded about when it should be the time to start scaling this horizontally because one day shit could happen (When it’s most needed - rule of thumb).
We run chef-client every 30min. + 15min. of splay time.
First, what you have to do is eliminate all possible *:*, name:*, fqdn:* or any other wildcard searches in your recipes. This is basically handled in erchef which is as I said before CPU-hungry. That means, you fetch all attributes from PostgreSQL (backend) and parse them in Erlang. Instead of fetching from Solr (already chewed).
In our case queries like fqdn:* eat 16 cores (nice and easy).
The next step was to replace all search() calls with filtered searches. That reduces the load for the erchef process and overall.
One more thing to consider is to review all possible iterations through data_bag_item() and replace it to search(:something, 'id:*'). Erchef does not like this much, but eventually, it’s good enough.
Before optimizations, we had converged time around 15-30min. It depends on the location. We had Geo distributed nodes with a single Chef Server in Europe while nodes are everywhere: US, SG, BR, ID, everywhere.
After optimizations converge time dropped to 5-20min. or so. Well, almost half-cut. Not bad, not good.
But still, there are searches that can’t be replaced for fqdn:* due to limitations in our infrastructure. Erchef is still angry about that. Decided to replace our standalone Chef Server with tiered architecture. One backend and multiple frontend servers. Two frontends per location with anycast for load balancing and high availability.
Backup standalone Chef Server instance and do restore on new frontends. That’s it, you need to change configs only afterward.
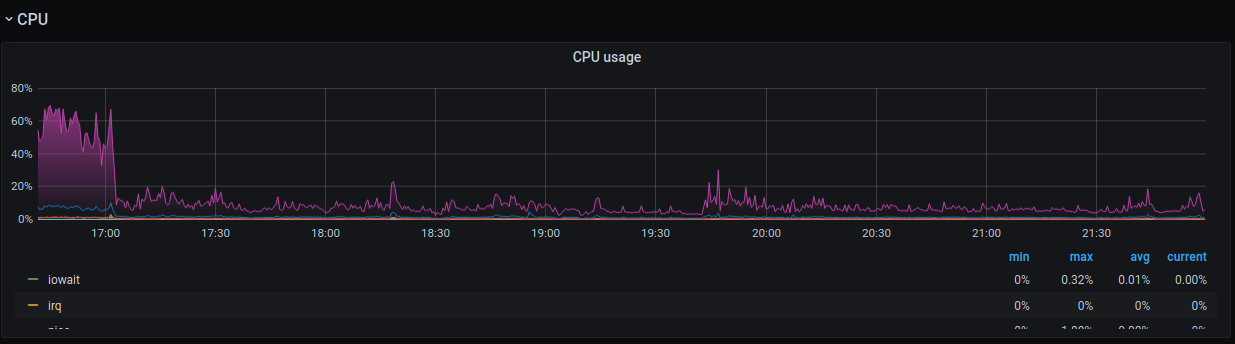
This is the graph (CPU drop) after launched frontend servers. Erchef is happy as never before.
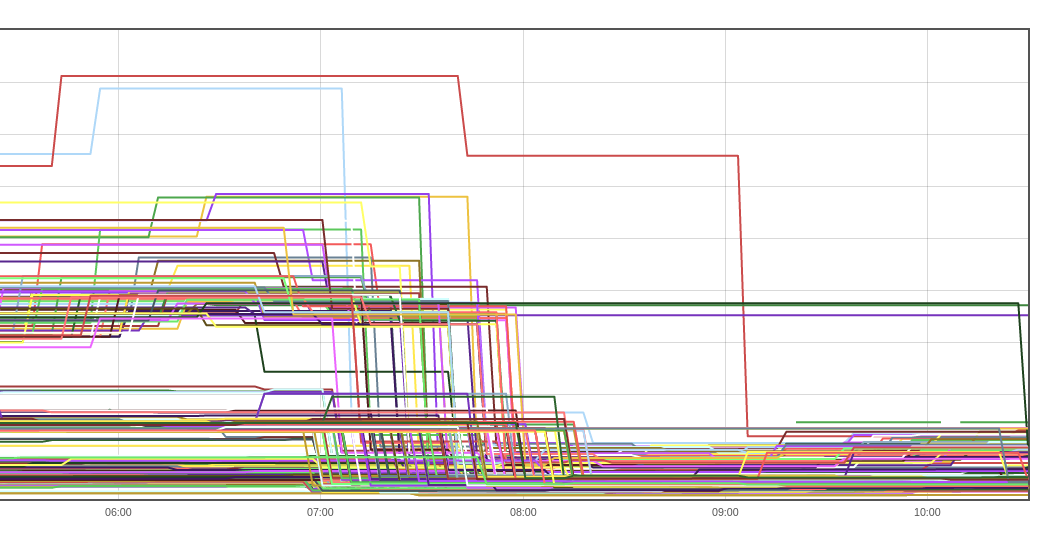
chef-client converge time dropped noticeably.
Still, the problem is that frontends are scaled per region while the backend is single (especially PostgreSQL). From Singapore to UK or so, latency is around 160-300ms, it depends on the conditions how the traffic is routed. We had a problem with one of our ISPs in Singapore and download bandwidth dropped below 1Mbps. And guess what. The chef stopped working at all, every queries to the backend timed out. When this happens, even 10s timeout is not enough. The biggest problem was due to (again) fqdn:* searches which consume sort of more traffic and causes timeouts. For non-wildcards queries that were basically good enough if the response size was around 100Kb.
Started thinking quickly about what to do here. Decided to launch pgpool-II instances as a sidecar to Chef frontends and separate memcached instances per region to cache data from pgpool-II.
Cache hit ratio to memcached instances isn’t high, around 10%, but that’s enough to offload wildcard searches.
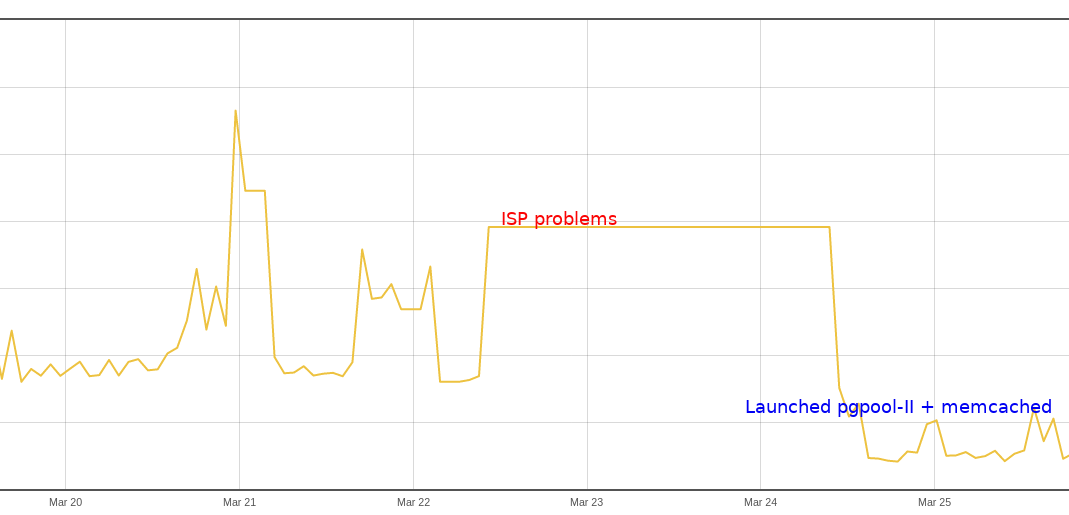
And now, we have converge time dropped to 1-5min.
The traffic to the backend server from frontends dropped by half from ~500mbps to ~250mbps.
FIN
I hope this post will be handy for others looking for similar problems.
Bonus - pgpool.conf
listen_addresses = 'localhost'
port = 31337
socket_dir = '/tmp'
listen_backlog_multiplier = 2
pcp_listen_addresses = 'localhost'
pcp_port = 9898
pcp_socket_dir = '/tmp'
backend_hostname0 = 'chef-backend.donatas.net'
backend_port0 = 5432
enable_pool_hba = off
pool_passwd = 'something'
authentication_timeout = 120
num_init_children = 32
max_pool = 16
child_life_time = 900
child_max_connections = 1000
connection_life_time = 600
pid_file_name = '/var/run/pgpool/pgpool.pid'
logdir = '/var/log/pgpool'
connection_cache = on
memory_cache_enabled = on
memqcache_method = 'memcached'
memqcache_memcached_host = 'chef-memcached.donatas.net'
memqcache_memcached_port = 11211
memqcache_total_size = 134217728
memqcache_max_num_cache = 10000000
memqcache_expire = 14400
memqcache_auto_cache_invalidation = on
memqcache_maxcache = 1048576
memqcache_cache_block_size = 2097152
memqcache_oiddir = '/var/log/pgpool/oiddir'
white_memqcache_table_list = ''
black_memqcache_table_list = ''
Bonus - frontend config
nginx['enable_ipv6'] = true
nginx['ssl_certificate'] = '/var/opt/opscode/nginx/ca/donatas.net.crt'
nginx['ssl_certificate_key'] = '/var/opt/opscode/nginx/ca/donatas.net.key'
opscode_erchef['depsolver_worker_count'] = 8
opscode_expander['nodes'] = 8
opscode_erchef['nginx_bookshelf_caching'] = ':on'
opscode_erchef['s3_url_expiry_window_size'] = '100%'
opscode_erchef['db_pool_queue_max'] = 32
opscode_erchef['db_pooler_timeout'] = 300000
opscode_erchef['depsolver_pool_queue_max'] = 10
opscode_erchef['depsolver_pooler_timeout'] = 300000
opscode_erchef['db_pool_size'] = 16
opscode_erchef['sql_db_timeout'] = 300000
opscode_erchef['authz_timeout'] = 300000
oc_bifrost['db_pooler_timeout'] = 300000
oc_bifrost['db_pool_queue_max'] = 32
oc_bifrost['db_pool_size'] = 16
lb['cache_cookbook_files'] = true
lb['redis_connection_timeout'] = 300000
lb['redis_keepalive_timeout'] = 300000
postgresql['vip'] = '127.0.0.1'
postgresql['port'] = 31337
topology 'tier'
server 'backend1.donatas.net',
:ipaddress => 'X.X.X.X',
:role => 'backend',
:bootstrap => true
backend_vip 'backend1.donatas.net',
:ipaddress => 'X.X.X.X,
:device => 'ens192'
server 'frontend1.donatas.net',
:ipaddress => 'Y.Y.Y.1',
:role => 'frontend'
server 'frontend2.donatas.net',
:ipaddress => 'Y.Y.Y.2',
:role => 'frontend'
server 'frontend3.donatas.net',
:ipaddress => 'Y.Y.Y.3',
:role => 'frontend'
server 'frontend4.donatas.net',
:ipaddress => 'Y.Y.Y.4',
:role => 'frontend'
...
api_fqdn 'chef.donatas.net'