IPv6 as a metadata store
It’s 2017, but I still have to tell people time to time what it is, how it works, what’s the benefit comparing with ancient protocol, how it differs and so on and so forth.
Although it has been around for years, it has only been until recently that IPv6 adoption has been gaining pace.
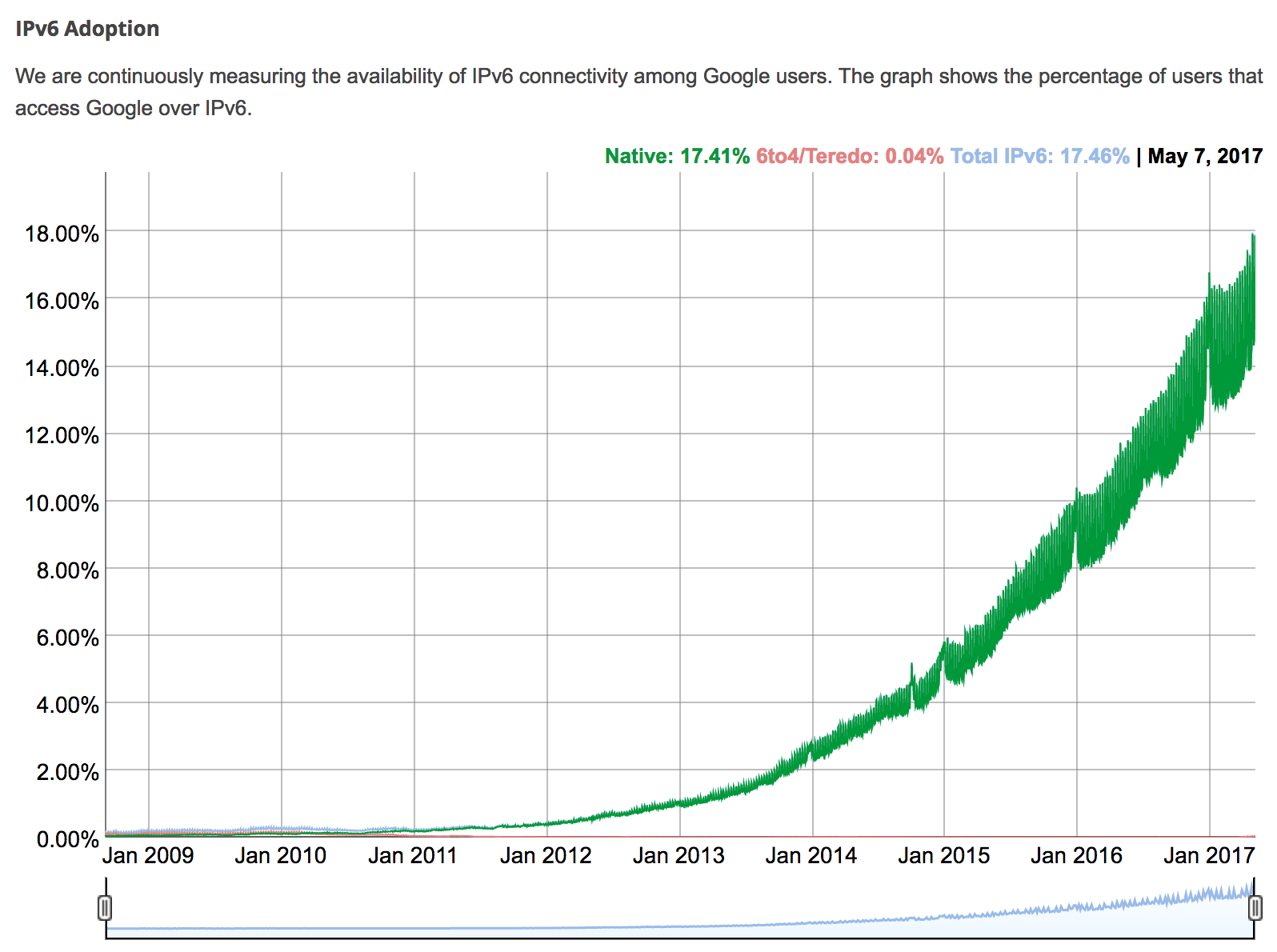
As you see in the picture below IPv6 adoption is getting pace. What does it mean? It means, that more and more devices are connecting to the internet (Internet of Things is trending these days) and they require to be reachable from outside bypassing well-known CG-NAT and other stuff. Even performance is nearly 10-15% better with IPv6, thus there is zero reason why not to start to use IPv6 this right now.
IPv6 is really matured with a huge address space which requires thinking differently. Hence, the first thing in this “new” protocol is addressing. The rules valid for IPv6 are not valid for IPv6 anymore, thus why do not exploit this capability for other purposes like storing some useful information (state, metadata, etc.) inside address space?
Some ISPs integrates such metadata inside IPv6 address like VLAN, VXLAN, department, building, service, tag, even the port (better to use DNS if IP would be changed in some circumstances) number could be mapped. I remember when we started to implement IPv6 at Vinted (it was my second IPv6 deployment) we brainstormed what would be the best way to divide this address space to be readable, practical and scalable. First iterations were too much overengineered as usually (too much metadata relied on address itself: service, data center, location). Eventually, this was enumerated the simplest way.
Another one more interesting approach for storing metadata info in IPv6 address is for sharding.
Sharding helps in cases when you want to spread your data across more than one node. And to keep this information consistent for read/write operations crucial to keep metadata somewhere for the client to know where to send data. You cannot send read requests to random nodes because data is not replicated. This makes IPv6 addresses a suitable place for such metadata.
For instance, let’s do sharding for three memcached instances. We have three nodes with appropriate addressing where the last four octets are delegated for start:end.
2a02:4780:1:1::0:3e7/64
2a02:4780:1:1::3e8:7cf/64
2a02:4780:1:1::7d0:bb7/64
The first node handles shards from zero to 0x03e7 and so on. Below is the minimal PoC how it works (I picked CRC16 algorithm to hash keys):
require 'digest/crc16'
class Sharding
def initialize(nodes, key)
@nodes = nodes
@key = key
@max_slots = max_slots
end
def max_slots
@nodes.each do |node|
octets = node.split(':')
shard_end = octets[octets.size - 1].hex
@max_slots = shard_end if shard_end > @max_slots
end
end
def get_shard
max_slots
@nodes.each do |node|
octets = node.split(':')
shard_start = octets[octets.size - 2].hex
shard_end = octets[octets.size - 1].hex
shard_hex = Digest::CRC16.hexdigest(@key).hex % @max_slots
return node if shard_hex >= shard_start && shard_hex <= shard_end
end
end
end
nodes = [
'2a02:4780:1:1::0:3e7',
'2a02:4780:1:1::3e8:7cf',
'2a02:4780:1:1::7d0:bb7'
]
p Sharding.new(nodes, 'example_key0').get_shard
p Sharding.new(nodes, 'example_key1').get_shard
This produces output:
% ruby sharding.rb
"2a02:4780:1:1::7d0:bb7"
"2a02:4780:1:1::0:3e7"
Keep in mind, that this method won’t work if you operate SLAAC inside your network, it relies on static IP addresses or DHCPv6. The best way would be to announce /128 from node (this task could be automated) unless you operate on L2-only network. As I mentioned above we need only last four bytes from IP address, hence /120 is enough. According to IPv6 addressing architecture /64 is given for host (it doesn’t matter if it’s point-to-point link or end customer), thus everyone is able to implement this approach.
Conclusion
- Algorithms are opinions embedded in code, while IPv6 address space is an extra storage for metadata;
- In practice there are two ways to implement things: popular or correct, pick one responsibly.